Automating investment research with Python.
My brother and I make investments by following Joel Greenblatt's Magic Formula. We use a site, magicformulainvesting.com, that uses this formula and outputs the top x companies that fit within the criteria of the formula. However, the site does not allow a user to copy the information of these companies from the webpage directly. Manually typing out the names of 30+ companies and their information is a time-suck, so I created this script to scrape this information instead.
Features
- opens a Chrome browser to the magic formula login page, then uses selenium's Keys and the getpass library to enter login information
- once logged in, selects the number of stocks to view and clicks the corresponding button to display them
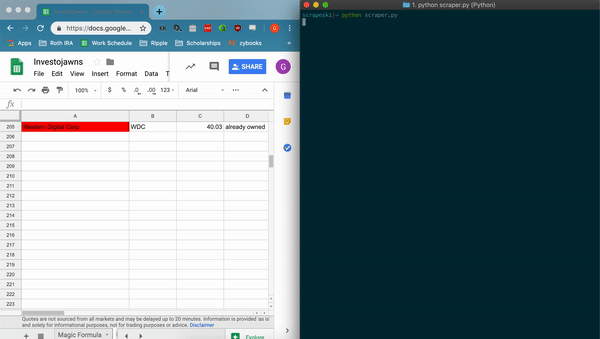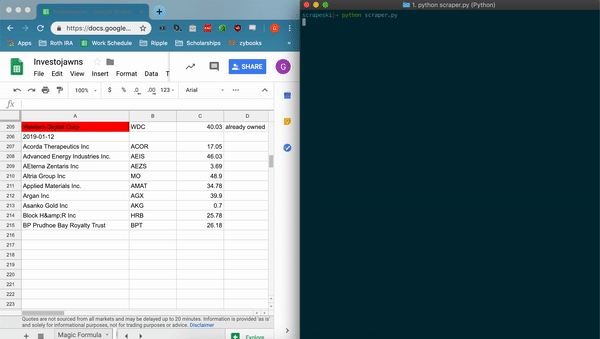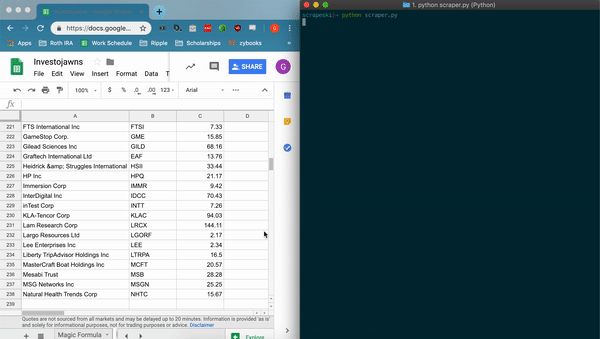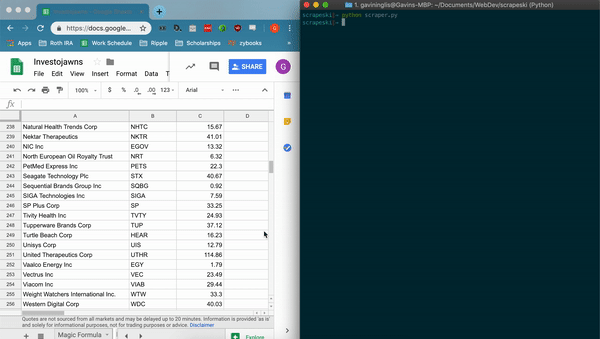
- scrapes information about listed companies, writes to csv file titled 'companies.csv'
- appends data to spreadsheet using the Google Sheets API and gspread
Cron Job
I have set up my script to run using a cron job every 3 months (quarterly) on the first of each month at 1 pm. To run selenium with a cron job, the browser used must be headless, meaning it doesn't have a GUI. I am using Chrome and giving it the option to run headless in my personal script. Chrome webdrivers must be installed for this to work with Chrome. Of course, any browser compatible with Selenium should work with this, so long as you have the appropriate webdriver for the browser and you specify to use that browser in the script.
Below is my cron job, accessed on Mac or Linux by running 'crontab -e' at the terminal. I first had to give iTerm and the Terminal apps permission in the system settings to read/write from my ssd.
SHELL=/bin/bash
PATH=/usr/local/bin/:/usr/bin:/usr/sbin
0 1 1 */3 * export DISPLAY=:0 && cd /path/to/scraper && /usr/bin/python scraper.pyFrom reading online, it sounds as though a cron job cannot read standard input and will generate an end of file error. So for the cronjob, I have hardcoded my username and password, which is really bad practice. However, since this site doesn't really contain sensitive information, I'm okay with that. The provided script in my Github repository for this project still uses the secure method provided by getpass to deal with the user's password.